MAFIA: MAximal Frequent Itemset Algorithm

MAFIA is a new algorithm for mining maximal frequent itemsets from a transactional database. Our algorithm is especially efficient when the itemsets in the database are very long. The search strategy of our algorithm integrates a depth-first traversal of the itemset lattice with effective pruning mechanisms.
Our implementation of the search strategy combines a vertical bitmap representation of the database with an efficient relative bitmap compression schema. In a thorough experimental analysis of our algorithm on real data, we isolate the effect of the individual components of the algorithm. Our performance numbers show that our algorithm outperforms previous work by up to an order of magnitude.
An animated gif demonstrates the MAFIA algorithm here.
{kind=link}
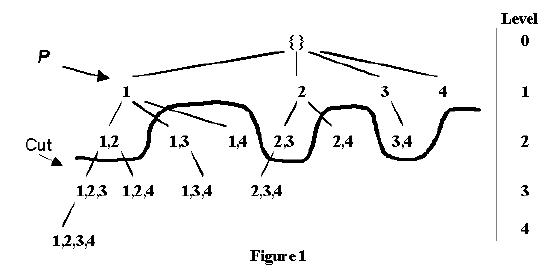
Candidate Itemset Tree
The process of generating candidate itemsets is done using a depth-first search, and the process can be represented as a candidate itemset tree. With each step down the tree, a single item is extended onto an itemset. As the itemsets grow larger and larger, the percentage of customers who have the itemset, or the support %, will grow smaller and smaller. Eventually, this support value will go below the minimum support required for an itemset to be deemed frequent.
When looking at the lexicographic tree, it is possible to draw a line that crosses all points at which an occurrence of an itemset being extended goes from frequent to infrequent. All itemsets directly above this line are termed the maximal frequent itemsets. By the Apriori principle, no itemset extensions below this line can be frequent since they all contain other itemsets within them that were found to be infrequent.
Search Space Pruning
We have found that in certain cases, branches of the candidate itemset tree can be "pruned" away, leading to fewer itemsets that need to be checked, and therefore a faster running time. This section explains what each of these pruning steps do.
Parent Equivalence Pruning - If an itemset in the tree has the same support as one of its candidate extensions, then it can be pruned from the tree because it must only occur in the database as part of that candidate extension.
HUTMFI Superset Pruning - If the union of an itemset and its leftmost tail on the ordered subtree is frequent then the entire subtree can be pruned away. This process checks the current list of maximal frequent itemsets to see if this head-union-tail is already on this list.
FHUT - Frequent Head-Union-Tail - This pruning method is identical to HUTMFI except it actually checks the support of the HUT rather than searching to see if it is already in the MFI list. FHUT has been found to yield fewer performance increases than HUTMFI.
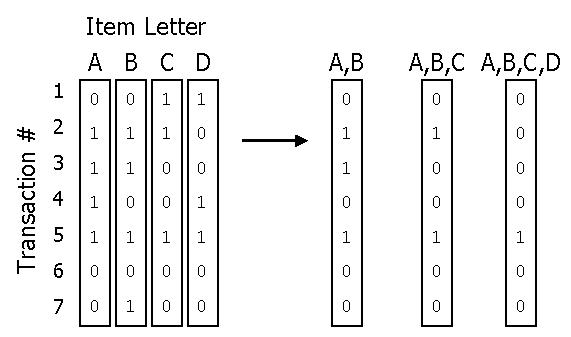
Vertical Bitmap Representation
MAFIA efficiently stores the transactional database as a series of vertical bitmaps, where each bitmap represents an itemset in the database and a bit in each bitmap represents whether or not a given customer has the corresponding itemset.
Initially, each bitmap corresponds to a 1-itemset, or a single item. The itemsets that are checked for frequency in the database become recursively longer and longer, and the vertical bitmap representation works perfectly in conjunction with this itemset extension. For example, the bitmap for the itemset (a,b) can be constructed simply by performing an AND operation on all of the bits in the bitmaps for (a) and (b). Then, to count the number of customers that have (a,b), all that needs to be done is count the number of one bits in the (a,b) bitmap equals the number of customers who have (a,b). Clearly, the bitmap structure is ideal for both candidate itemset generation and support counting.
Source Code Download
The SourceForge download page has instructions on downloading the last stable version of the code. You can also download the datasets used for testing.
CVS access is also available:
- Browse the source tree hosted at SourceForge: CVS Tree
- Type 'cvs -d:pserver:anonymous@cvs.sourceforge.net:/cvsroot/himalaya-tools login'
- Press Enter when prompted for a password.
- Type 'cvs -z3 -d:pserver:anonymous@cvs.sourceforge.net:/cvsroot/himalaya-tools co Mafia'
- A source tree rooted in a directory called Mafia will be created.
Contact
Please send email to  or contact the authors directly:
or contact the authors directly:
Publications
Doug Burdick,
Manuel Calimlim and
Johannes Gehrke.
MAFIA:
A Maximal Frequent Itemset Algorithm for Transactional Databases.
In Proceedings
of the 17th International Conference on Data Engineering.
Heidelberg, Germany, April 2001.